この記事は、pythonのpandasについて、以下のようなことを知りたい人のために書きました。
- pandasライブラリーのlocを使い方
- データフレームのある列について、条件による抽出をしたい
- データフレームのある列について、複数の条件で抽出したい
- pandasのloc機能を使わずに条件抽出する方法を知りたい(力技)
- pandasで株価解析をやってみたい
題材は、日本の株式市場の株価データを使います。無料で株価データをダウンロードする方法は、こちらで詳しく紹介しています。
pythonカスタム関数§07:download_mujinzo() 無尽蔵さんのサイトから指定日の全株価データをダウンロードする
また、pandasの基本的なことについては、以下の記事でも紹介していますので、参考にしてください。
python§03:データ分析ライブラリーpandasを徹底解説します
ライブラリーのインポート関連
今回使用するライブラリーをインポートします。
import datetime import pandas as pd from pandas import DataFrame,Series import requests import os import sys import numpy as np
下準備(株価データのダウンロード)
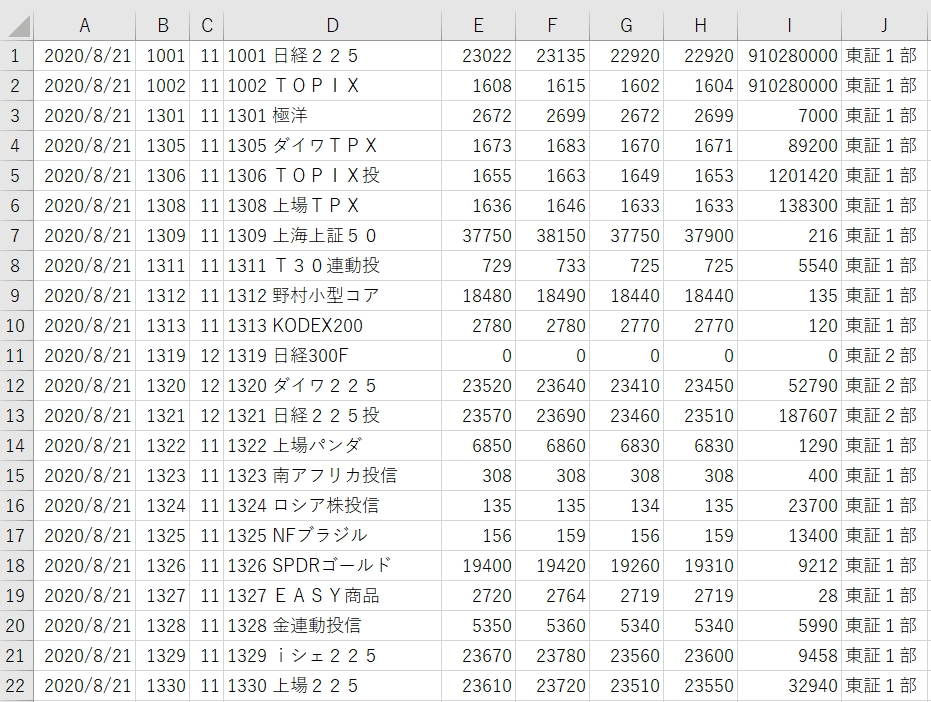
以下は、ダウンロードしてくるファイルをエクセルで開いた状態をキャプチャーしたものです。
左から 日付、銘柄コード、市場コード、銘柄名(code+名前)、始値、高値、安値、終値、出来高、市場名
の順番に並んでいます。列名は、date,code,no,name,open,high,low,close,volume,marketとします。
if __name__ == '__main__':
#スクリプトを実行するバッチファイルを生成
fname=os.path.splitext(os.path.basename(sys.argv[0]))[0]+'.bat'
with open(fname,'w') as f:f.write(f'python "{sys.argv[0]}" \n pause \n')
デバッグのときに楽なので、私はいつもこれをメインコードの先頭で入れるようにしています。バッチファイルを起動すれば、pythonが実行され、表示をいったん停止してくれます。このバッチファイルについては、この記事でも紹介しています。→
pythonカスタム関数§05:CreateBatfile() Pythonファイルを実行できるバッチファイルを自動生成
#print()で出力させるファイルを設定
f = open('memo.txt','w')
次にファイルをオープンしています。今回このmemo.txtには、一部、print()関数でファイル出力させようとしています。(print()関数についてはこちらへ)
#日付と保存フォルダを指定して、株価データをダウンロード
date_str='2020-08-21' #ここを変更して利用する
year, month, day = date_str.split('-')
fileName = 'T{0}{1}{2}.zip'.format(year[-2:], month, day)
無尽蔵さんのサイトから株価データをいただくわけですが、ファイル名が「T200821.zip」という形式になっていますので、format()関数を使って、ファイル名を生成しています。(format()関数に関してはこちらへ)
#ダウンロードファイルの存在を確認。なければ、ダウンロードを実行
if not os.path.exists(fileName):
fileName=download_mujinzo(date_str=date,folder='./')
else:
print(f'ファイル:{fileName}はすでにダウンロード済みです')
print('*'*30,file=f)
print(f'Download Filename:{fileName}',file=f)
print('*'*30,file=f)
ダウンロードを自動で行う関数 download_mujinzo() というカスタム関数(ユーザー定義関数)を使います。日付とダウンロードファイルの保存場所を指定するシンプルな使い方です。
この株価ダウンロード関数いついてはこちらで詳しく紹介しています。
pythonカスタム関数§07:download_mujinzo() 無尽蔵さんのサイトから指定日の全株価データをダウンロードする
今回、少し工夫したところは、if not os.path.exists(fileName) の判定です。
もし、ダウンロードファイルがまだ保存されていなければ実行するという文です。つまり、すでにダウンロードしていた場合は、実行しないということですね。サーバーの負荷を少しでも減らす配慮です。
ここまでを実行すると、ファイルがダウンロードされて、準備OKです。
pandasでzip(csv)ファイルを読み込む pandas.read_csv()
#zipファイルを読み込み、DataFrameに変換する → その後列名をセットする
df=pd.read_csv(fileName,encoding="shift_jis",header=None)
df.columns=['date','code','no','name','open','high','low','close','volume','market']#列名をセット
df=df.sort_values('code')
pandasには、read_csv関数という便利な機能が搭載されています。csvという名前ですが、実はzipのような圧縮ファイルも中身を自動で判断して、読み込んでくれます。すごい!!!
引数には ファイル名、エンコード、ヘッダーを設定しています。ファイル名だけでも読み込める場合がありますが、そのときはエンコードはUTF-8、ヘッダーは1行目をヘッダーとして使うことになります。
ここでは、さきほどのエクセル表を見て、ヘッダーがないことがわかりますので、header=Noneとします。(もし省略すると1行目のデータを消失してしまいますので、ご注意を)
そして、後先逆になりましたが、エンコードです。デフォルトではUTF-8という文字コードが選ばれるので、実はエラーで止まってしまいます。
こんな表示が出れば、UTF-8で変換しようとして失敗したというメッセージです。
ここでは、shift-JISを設定しておけば大丈夫です。
df.columns=[‘date’,’code’,’no’,’name’,’open’,’high’,’low’,’close’,’volume’,’market’]
で、列名をセットしています。columnsにリストを渡せば設定できます。ここで、注意すべきは、列数を一致させないといけないことです。たとえば、列名が不足していると
という具合に要素数が10あるのに設定しようとしているのは9個だからダメよんと言っています。
逆に多すぎる場合もエラーが出てしまいます。CSVをエクセルで確かめるか、df.info()などを使って、データ列数を下調べしておくとよいですね。
次の df=df.sort_values(‘code’) は、銘柄コード番号でソートするという意味です。順番を並び替えて、コードが若い順にすることができます。df変数に入れなおしていますが、別の変数を新たに作ってもいいです。
#データフレームの内容を表示 year, month, day = date_str.split('-')
print('*'*10,'DataFrame information','*'*10)
print(df.info()) #各列の情報
print('*'*10,'DataFrame first 10 data ','*'*10)
print(df.head(50)) #先頭10個のデータ表示
print('*'*30)
<class ‘pandas.core.frame.DataFrame’>
Int64Index: 4054 entries, 0 to 4053
Data columns (total 11 columns):
# Column Non-Null Count Dtype
— —— ————– —–
0 date 4054 non-null object
1 code 4054 non-null int64
2 no 4054 non-null int64
3 name 4054 non-null object
4 open 4054 non-null float64
5 high 4054 non-null float64
6 low 4054 non-null float64
7 close 4054 non-null float64
8 volume 4054 non-null int64
9 market 4054 non-null object
10 name2 4054 non-null object
dtypes: float64(4), int64(3), object(4)
memory usage: 380.1+ KB
********** DataFrame first 10 data **********
date code no name open high low close volume market name2
0 2020/8/21 1001 11 1001 日経225 23022.0 23135.0 22920.0 22920.0 910280000 東証1部 日経225
1 2020/8/21 1002 11 1002 TOPIX 1608.0 1615.0 1602.0 1604.0 910280000 東証1部 TOPIX
2 2020/8/21 1301 11 1301 極洋 2672.0 2699.0 2672.0 2699.0 7000 東証1部 極洋
3 2020/8/21 1305 11 1305 ダイワTPX 1673.0 1683.0 1670.0 1671.0 89200 東証1部 ダイワTPX
4 2020/8/21 1306 11 1306 TOPIX投 1655.0 1663.0 1649.0 1653.0 1201420 東証1部 TOPIX投
5 2020/8/21 1308 11 1308 上場TPX 1636.0 1646.0 1633.0 1633.0 138300 東証1部 上場TPX
6 2020/8/21 1309 11 1309 上海上証50 37750.0 38150.0 37750.0 37900.0 216 東証1部 上海上証50
7 2020/8/21 1311 11 1311 T30連動投 729.0 733.0 725.0 725.0 5540 東証1部 T30連動投
8 2020/8/21 1312 11 1312 野村小型コア 18480.0 18490.0 18440.0 18440.0 135 東証1部 野村小型コア
9 2020/8/21 1313 11 1313 KODEX200 2780.0 2780.0 2770.0 2770.0 120 東証1部 KODEX200
10 2020/8/21 1319 12 1319 日経300F 0.0 0.0 0.0 0.0 0 東証2部 日経300F
11 2020/8/21 1320 12 1320 ダイワ225 23520.0 23640.0 23410.0 23450.0 52790 東証2部 ダイワ225
12 2020/8/21 1321 12 1321 日経225投 23570.0 23690.0 23460.0 23510.0 187607 東証2部 日経225投
13 2020/8/21 1322 11 1322 上場パンダ 6850.0 6860.0 6830.0 6830.0 1290 東証1部 上場パンダ
14 2020/8/21 1323 11 1323 南アフリカ投信 308.0 308.0 308.0 308.0 400 東証1部 南アフリカ投信
15 2020/8/21 1324 11 1324 ロシア株投信 135.0 135.0 134.0 135.0 23700 東証1部 ロシア株投信
16 2020/8/21 1325 11 1325 NFブラジル 156.0 159.0 156.0 159.0 13400 東証1部 NFブラジル
17 2020/8/21 1326 11 1326 SPDRゴールド 19400.0 19420.0 19260.0 19310.0 9212 東証1部 SPDRゴールド
18 2020/8/21 1327 11 1327 EASY商品 2720.0 2764.0 2719.0 2719.0 28 東証1部 EASY商品
19 2020/8/21 1328 11 1328 金連動投信 5350.0 5360.0 5340.0 5340.0 5990 東証1部 金連動投信
20 2020/8/21 1329 11 1329 iシェ225 23670.0 23780.0 23560.0 23600.0 9458 東証1部 iシェ225
21 2020/8/21 1330 11 1330 上場225 23610.0 23720.0 23510.0 23550.0 32940 東証1部 上場225
22 2020/8/21 1332 11 1332 日水 483.0 488.0 477.0 477.0 752700 東証1部 日水
23 2020/8/21 1333 11 1333 マルハニチロ 2270.0 2291.0 2255.0 2255.0 86600 東証1部 マルハニチロ
24 2020/8/21 1343 11 1343 NF東REIT 1814.0 1855.0 1813.0 1852.0 341560 東証1部 NF東REIT
25 2020/8/21 1344 11 1344 MXコア 714.0 714.0 705.0 705.0 5390 東証1部 MXコア
26 2020/8/21 1345 11 1345 上場Jリート 1725.0 1761.0 1724.0 1761.0 633500 東証1部 上場Jリート
27 2020/8/21 1346 11 1346 MX225投信 23680.0 23790.0 23560.0 23610.0 8728 東証1部 MX225投信
28 2020/8/21 1348 11 1348 MAXトピックス 1654.0 1664.0 1650.0 1653.0 7950 東証1部 MAXトピックス
29 2020/8/21 1349 11 1349 ABFアジア 12710.0 12770.0 12710.0 12710.0 6 東証1部 ABFアジア
30 2020/8/21 1352 11 1352 ホウスイ 881.0 886.0 878.0 878.0 500 東証1部 ホウスイ
31 2020/8/21 1356 11 1356 TOPXベア 1884.0 1898.0 1863.0 1891.0 250000 東証1部 TOPXベア
32 2020/8/21 1357 11 1357 日経ダブル 736.0 744.0 730.0 742.0 43814121 東証1部 日経ダブル
33 2020/8/21 1358 11 1358 上場日経2倍 18870.0 19060.0 18710.0 18730.0 10682 東証1部 上場日経2倍
34 2020/8/21 1360 11 1360 日経ベア2倍投 1791.0 1809.0 1775.0 1804.0 2162080 東証1部 日経ベア2倍投
35 2020/8/21 1364 11 1364 JPX日経400ETF 14740.0 14740.0 14740.0 14740.0 2 東証1部 JPX日経400ETF
36 2020/8/21 1365 11 1365 大和225ダブル 15500.0 15650.0 15370.0 15400.0 44509 東証1部 大和225ダブル
37 2020/8/21 1366 11 1366 大和225Wベア 1920.0 1939.0 1903.0 1934.0 334177 東証1部 大和225Wベア
38 2020/8/21 1367 11 1367 大和TPXダブル 12490.0 12640.0 12420.0 12470.0 1764 東証1部 大和TPXダブル
39 2020/8/21 1368 11 1368 大和TPXWベア 2739.0 2760.0 2710.0 2748.0 65138 東証1部 大和TPXWベア
40 2020/8/21 1369 11 1369 DIAM 日経225 23090.0 23110.0 22940.0 22940.0 2239 東証1部 DIAM
41 2020/8/21 1376 11 1376 カネコ種 1419.0 1419.0 1405.0 1405.0 700 東証1部 カネコ種
42 2020/8/21 1377 11 1377 サカタタネ 3485.0 3535.0 3445.0 3480.0 41000 東証1部 サカタタネ
43 2020/8/21 1379 11 1379 ホクト 2160.0 2168.0 2152.0 2162.0 71800 東証1部 ホクト
44 2020/8/21 1380 91 1380 秋川牧園 1110.0 1110.0 1091.0 1102.0 12100 JAQ 秋川牧園
45 2020/8/21 1381 91 1381 アクシーズ 2811.0 2830.0 2811.0 2814.0 700 JAQ アクシーズ
46 2020/8/21 1382 91 1382 ホープ 975.0 975.0 962.0 969.0 2000 JAQ ホープ
47 2020/8/21 1383 91 1383 ベルグアース 2111.0 2139.0 2111.0 2130.0 600 JAQ ベルグアース
48 2020/8/21 1384 11 1384 ホクリョウ 638.0 648.0 638.0 648.0 5400 東証1部 ホクリョウ
49 2020/8/21 1385 11 1385 ETFユーロ大型株 4215.0 4215.0 4115.0 4125.0 49 東証1部 ETFユーロ大型株
******************************
このように df.info()やdf.head()、df.tail()などで先頭や最後の少しのデータを表示させる機能も使いましょう。df.head(10)とすれば、10行分だけ表示させることができます。
head()の表示結果は、桁がそろっていなくて、見にくいですね。これは、あとで改善することにしましょう。
銘柄リスト出力 (DataFrameをndarrayに変換して加工する)
最初の課題「銘柄コード」をCSVに出力させることをやってみましょう。
素直にdf.to_csv()というCSV書き出し機能を使ったもできるのですが、エクセルの図を見ると、株価データの中の銘柄名が「銘柄コード」+「 」+「銘柄名」という形なので、銘柄名だけを取り出したいと思いました。
#csvファイルに書き出す 銘柄リスト出力
code,no,name,open,high,low,close,volume,market,date = kabu_df2ndarray(df)
name2=[]
for i in range(len(df)):
try:
name2.append(name[i].split(' ')[1].strip())
except:
name2.append(name[i])
df['name2']=name2
savefile='./code_list.csv'
df[['code','name2']].to_csv(savefile,encoding='utf_8_sig') #UTF-8 BOM付ファイル書き込み エクセルで文字化け防止
ここで、先頭行に
kabu_df2ndarray(df)
という怪しげな関数が登場しました。これもユーザー定義関数で、以下のようなコードとなっています。
def kabu_df2ndarray(df):
code = df['code'].values
no = df['no'].values
name = df['name'].values
open = np.array(df['open'].values, dtype=np.int64) #float→intに変換
high = np.array(df['high'].values, dtype=np.int64) #float→intに変換
low = np.array(df['low'].values, dtype=np.int64) #float→intに変換
close = np.array(df['close'].values, dtype=np.int64) #float→intに変換
volume = df['volume'].values
market = df['market'].values
date = df['date'].values
return code,no,name,open,high,low,close,volume,market,date
この関数の中では、基本的には、numpyのndarrayという多次元リストに変換しているだけです。ここでは、多次元だけではなく、列のみのデータなので1次元リストです。
np.arrayによって、変数の型の変換を行うことができます。open,high,low,closeは元のデータはfloatですが、整数にしたほうが見やすいと考え、int変換しています。
そして、最後のreturn文で変換したndarrayをすべて戻しています。
for文以降で、銘柄名だけを取り出す加工をしています。
name2.append(name[i].split(‘ ‘)[1].strip())
name[i]をスペースで分離して、右側の文字列だけを取り出して、空白文字を除去しています(strip())
ここで、try文を使っているのは、1~2個の銘柄のみ、スペースがなかったり、スペースが2つあったりしたので、エラー処理をしています。ほとんどの銘柄名はうまく処理できています。
市場の種類をリスト化 unique()
pandasのSeriesの機能ですが、ユニークな要素を取得する機能です。つまり、重複している要素はすべて1種類とします。やったほうが早いですね。
#市場の種類をリスト化
market_list=df['market'].unique()
print(market_list,file=f)
#['東証1部' '東証2部' 'JAQ' '東証マ' '名古セ' '名証1部' '外国' '名証2部' '名証セ' '東証M']matket_listという新しい変数にdf[‘market’]というSeriesデータにunique()を使って、要素を取り出します。
結果、東証1部、以下10個のマーケットの種類が抽出できました。
(おそらく東証マと東証Mは同じかな?・・)
さらに、この要素には何個のデータがあるのか調べることができます。
print(df['market'].value_counts(),file=f)
#東証1部 2462
#JAQ 696
#東証2部 488
#東証マ 335
#名証2部 51
#名証セ 12
#名証1部 6
#外国 2
#名古セ 1
#東証M 1
東証1部の銘柄が2462、JAQが696、東証2部が488という具合です。
locにより条件抽出する
やっとlocにたどりつきました。
print('データを整形して桁をそろえて表示させる【東証1部】',file=f)
df1=df.loc[df['market']=='東証1部' ]
kabu_seikei(df1,1,30)
kabu_seikei2(df1,1,30,f=f)
表示をきれいに整形することにもチャレンジしますが、まずはlocですね。
df1=df.loc[df[‘market’]==’東証1部’ ]
これを翻訳すると、df[‘market’]のSeriesデータが’東証1部’と同じものを取り出す命令となっています。==は、if文のときと同じで、イコール二つに注意してください。
この演算を行えば、df1というサブセットが出来上がります。dfに入れてしまうと、東証一部以外のデータを取り出すことができなくなるので、サブセットとしました。
kabu_seikei()とkabu_seikei2()という二つのユーザー定義関数は、さきほどの表示の不具合、桁がそろわない問題を解決するものです。kabu_seikei2は、ファイルに出力する以外は、kabu_seikeiと同じなので、kabu_seikei()について説明します。
def kabu_seikei(df,start=1,end=30):
#DataFrameをndarrayに変換してリストのように扱えるようにする
code,no,name,open,high,low,close,volume,market,date = kabu_df2ndarray(df)
start=start-1
end=end-1
#データを整形して桁をそろえて表示させる
print('{:5} {:4} {:2} {:^20} {:>10} {:>10} {:>10} {:>10} {:>10} {:<10} {:}'.format ('No','code','no','name','open','high','low','close','volume','market','date')) print('-'*120) for i in range(len(df)): if i>=start and i<=end:
print('{:5} {} {} {} {:10} {:10} {:10} {:10} {:10} {:10} {:}'.format
(i+1,code[i],no[i],haba_cal(name[i].split(' ')[1].strip(),haba=20,embedded='',hoko='<')
,open[i],high[i],low[i],close[i],volume[i],haba_cal(market[i],haba=10,embedded='',hoko='<'),date[i]))
else:
break
引数は、データフレーム、開始番号、終了番号です。ひとつめのデータから表示したい場合は1とします。終了番号も5番目のデータまで表示したい場合は5とします。
さきほどのkabu_df2ndarray(df) を使って、ndarrayに変換します。
そして、泥臭いですが、for文で最初から最後まで1行ずつ処理していきます。
fomart()関数を使って、文字幅を決めたり、右寄せや左寄せなども設定しています。半角と全角が混在している部分をhaba_cal()というユーザー定義関数を使って、全角は2文字分、半角は1文字分として計算します。(※おそらくdf.head()などで桁がそろわないのは、全角も1文字分として計算してしまうからだと思います)
このhaba_cal()については、別の記事で紹介しています。→
pythonカスタム関数§01:haba_cal() 半角1文字、全角2文字として正確な文字幅を決める
そして、結果が以下のとおりです。HTMLの関係か、普通に貼り付けると桁が不揃いなので、画面をキャプチャーしました。
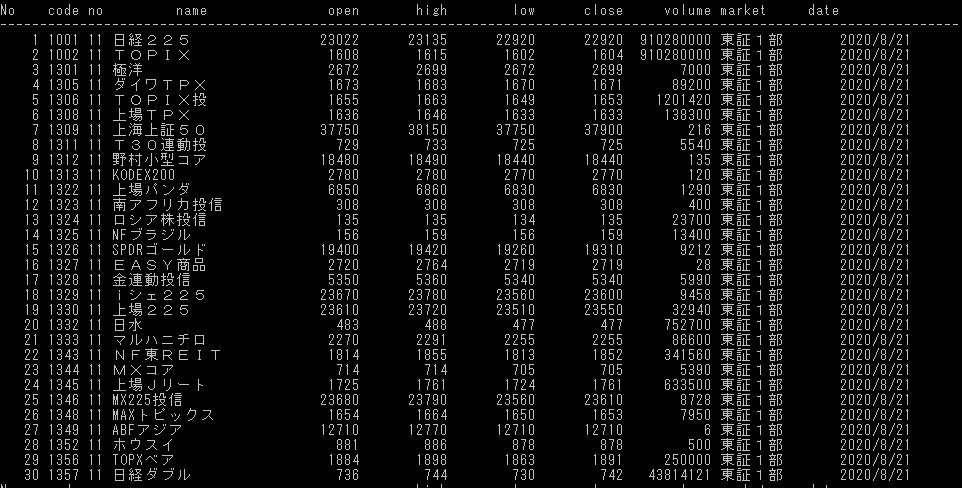
以上のように、locを使って1条件での抽出は簡単にできました。
その他、東証2部、東証マザーズ、JAQなどのコード例は以下のとおりです。
#データを整形して桁をそろえて表示させる【東証2部】
print('データを整形して桁をそろえて表示させる【東証2部】',file=f)
df2=df.loc[df['market']=='東証2部' ]
kabu_seikei(df2,1,30)
kabu_seikei2(df2,1,30,f=f)
#データを整形して桁をそろえて表示させる【東証マ】
print('データを整形して桁をそろえて表示させる【東証マ】',file=f)
dfm=df.loc[df['market']=='東証マ' ]
kabu_seikei(dfm,1,30)
kabu_seikei2(dfm,1,30,f=f)
#データを整形して桁をそろえて表示させる【JAQ】
print('データを整形して桁をそろえて表示させる【JAQ】',file=f)
dfJ=df.loc[df['market']=='JAQ' ]
kabu_seikei(dfJ,1,30)
kabu_seikei2(dfJ,1,30,f=f)
locを使って、複数条件で抽出するには
#複数の市場のデータを抽出する 【東証1部】or【東証2部】
print('複数の市場のデータを抽出する 【東証1部】or【東証2部】',file=f)
df1_2=df.loc[(df['market']=='東証1部')| (df['market']=='東証2部')]
わかってみれば、簡単なもので、ORなら|、ANDなら&で接続すればいいだけです。
locを使って、演算結果から条件抽出するには
今回の例題は、「売買代金」が〇〇億円以上の銘柄を抽出したい とします。
売買代金=終値×出来高 と定義します。
売買代金が大きい銘柄は「流動性が高い」と言われており、株式売買において、売りたいときに売りやすく、買いたいとき買いやすいという意味です。つまり売買代金の大きな銘柄を選定して売買することは、利益を出しやすい銘柄選定のひとつの戦略だと言えます。
#全データから売買代金が20億円以上の銘柄を抽出する
print('全データから売買代金が20億円以上の銘柄を抽出する',file=f)
df['baibai'] = df['close']*df['volume']/100000000
df_baibai=df.loc[df['baibai']>=20]
df_baibai=df_baibai.sort_values('baibai',ascending=False)
このコードでは、売買代金が20億円以上の銘柄を抽出するためのコードです。
まず df[‘close’]×df[‘volume’]で売買代金を計算し、100000000で割って単位を億にしています。
そしてその結果を新しい列「baibai」を作って、代入しています。
df_baibai=df.loc[df[‘baibai’]>=20]によって、20億円以上の銘柄を抽出して、df_baibaiというサブセットを作っています。
df_baibai=df_baibai.sort_values(‘baibai’,ascending=False) では、baibai列でソートして、降順に並べ替えています。デフォルトでは昇順なので、ascending=Falseとして、降順設定としています。
始値→高値 の割合が高い銘柄を抽出
ここからは、コード例ですが、株価解析のヒントになるかもしれません。始値から高値までの上昇率が高い銘柄を抽出します。ソートで上昇率の高い銘柄順にしています。さらに東証1部の銘柄に絞っています。
#始値→高値の割合が高い順
df['oh_ratio'] = (df['high']-df['open'])/df['open']*100
df_oh=df.sort_values('oh_ratio',ascending=False)
df_oh=df_oh.loc[df_oh['market']=='東証1部' ]
locの使い方まとめ
以上のようにpandasのlocを使えば、条件による抽出が簡単に行えます。
しかし、条件を記述する文が難しい、あるいはできない場合もあるので、スピードが遅くなることが我慢できるのであれば、ndarrayにして、for文で抽出するという手があります。
#ndarrayでfor文を使った抽出例
code,no,name,open,high,low,close,volume,market,date = kabu_df2ndarray(df)
oh_ratio=[]
for i in range(len(df)):
oh_ratio.append(((high[i]-open[i])/open[i])*100)
df['oh_ratio2']=oh_ratio
df_oh=df.sort_values('oh_ratio2',ascending=False)
df_oh=df_oh.loc[df_oh['market']=='東証1部' ]
#表示整形するために再度、ndarray化する
code,no,name,open,high,low,close,volume,market,date = kabu_df2ndarray(df_oh)
oh_ratio = df_oh['oh_ratio'].values
#データを整形して桁をそろえて表示させる【始値→高値の上昇率ソートで抽出】
print('{:5} {:4} {:2} {:^30} {:>10} {:>10} {:>10} {:>10} {:>10} {:<15} {:>10} {:<20}'.format ('No','code','no','name','open','high','low','close','volume','market','date','high-open ratio'),file=f) print('-'*120,file=f) start=1 end=50 start=start-1 end=end-1 for i in range(len(df_oh)): if i>=start and i<=end: print('{:5} {} {} {} {:10} {:10} {:10} {:10} {:10} {:10} {:>10} {:>4.1f}'.format
(i+1,code[i],no[i],haba_cal(name[i],haba=30,embedded='',hoko='<')
,open[i],high[i],low[i],close[i],volume[i],haba_cal(market[i].strip(),haba=15,embedded='',
hoko='<'),date[i],oh_ratio[i]),file=f)
else:
break
print('*'*120,file=f)
このようにndarrayに変換してからfor文で処理を行う方法が理解できると、どんな処理(加工)もできるので、鬼に金棒かもしれません。ただし、速度の犠牲やコードの見やすさは犠牲にしていますので、どうしてもpandasのlocで条件が書ききれないと思ったら、あまり悩まずにこの手を使うのもありだと思います。
今回の全ソースコード
import datetime
import pandas as pd
from pandas import DataFrame,Series
import requests
import os
import sys
import numpy as np
pd.set_option('display.width', 250) #表示幅を変更
pd.set_option("display.max_columns", 25) #最大表示列数
pd.set_option("display.max_colwidth", 80) #列の最大文字数
pd.set_option("display.max_rows", 200) #最大表示行数
def get_east_asian_width_count(text):
import unicodedata
#半角と全角の幅を求める(半角:1 全角:2)
count = 0
for c in text:
if unicodedata.east_asian_width(c) in 'FWA':
count += 2
else:
count += 1
return count
def haba_cal(s,haba=20,embedded='',hoko='<'):
#半角と全角混在でも幅を揃える文字を返す
#s:文字列 haba:揃えたい文字数
#embeged:埋め込みい文字
#hoko:左寄せ< 中央揃え^ 右寄せ>
n=get_east_asian_width_count(s)
new_haba=haba+len(s)-n
ss='{:'+embedded+hoko+str(new_haba)+'}'
final_s=ss.format(s)
return final_s
#F - East Asian Full-width
#H - East Asian Half-width
#W - East Asian Wide
#Na - East Asian Narrow (Na)
#A - East Asian Ambiguous (A)
#N - Not East Asian
def download_mujinzo(date_str='2020-08-21',folder='./'):
#無尽蔵さんから指定日付の株価データをダウンロード
year, month, day = date_str.split('-')
fileName = 'T{0}{1}{2}.zip'.format(year[-2:], month, day)
url= 'http://mujinzou.com/d_data/{0}d/{1}_{2}d/{3}'.format(year, year[-2:], month, fileName) #2020
filename = url.split('/')[-1]
r = requests.get(url, stream=True)
if "" in str(r):
filepath=os.path.join(folder, filename)
with open(filepath, 'wb') as f:
for chunk in r.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
f.flush()
print(f'Download Success:{filename}')
else:
print('Open Error')
return filename
def kabu_df2ndarray(df):
code = df['code'].values
no = df['no'].values
name = df['name'].values
open = np.array(df['open'].values, dtype=np.int64) #float→intに変換
high = np.array(df['high'].values, dtype=np.int64) #float→intに変換
low = np.array(df['low'].values, dtype=np.int64) #float→intに変換
close = np.array(df['close'].values, dtype=np.int64) #float→intに変換
volume = df['volume'].values
market = df['market'].values
date = df['date'].values
return code,no,name,open,high,low,close,volume,market,date
def kabu_seikei(df,start=1,end=30):
#DataFrameをndarrayに変換してリストのように扱えるようにする
code,no,name,open,high,low,close,volume,market,date = kabu_df2ndarray(df)
start=start-1
end=end-1
#データを整形して桁をそろえて表示させる
print('{:5} {:4} {:2} {:^20} {:>10} {:>10} {:>10} {:>10} {:>10} {:<10} {:}'.format ('No','code','no','name','open','high','low','close','volume','market','date')) print('-'*120) for i in range(len(df)): if i>=start and i<=end:
print('{:5} {} {} {} {:10} {:10} {:10} {:10} {:10} {:10} {:}'.format
(i+1,code[i],no[i],haba_cal(name[i].split(' ')[1].strip(),haba=20,embedded='',hoko='<')
,open[i],high[i],low[i],close[i],volume[i],haba_cal(market[i],haba=10,embedded='',hoko='<'),date[i])) else: break def kabu_seikei2(df,start=1,end=30,f=''):#fはファイルオブジェクトを渡すこと #DataFrameをndarrayに変換してリストのように扱えるようにする(出力はファイルへ) code,no,name,open,high,low,close,volume,market,date = kabu_df2ndarray(df) start=start-1 end=end-1 #データを整形して桁をそろえて表示させる print('{:5} {:4} {:2} {:^20} {:>10} {:>10} {:>10} {:>10} {:>10} {:<15} {:>10}'.format
('No','code','no','name','open','high','low','close','volume','market','date'),file=f)
print('-'*100,file=f)
for i in range(len(df)):
if i>=start and i<=end: print('{:5} {} {} {} {:10} {:10} {:10} {:10} {:10} {:10} {:>10}'.format
(i+1,code[i],no[i],haba_cal(name[i].split(' ')[1].strip(),haba=20,embedded='',hoko='<')
,open[i],high[i],low[i],close[i],volume[i],haba_cal(market[i].strip(),haba=15,embedded='',
hoko='<'),date[i]),file=f)
else:
break
print('*'*120,file=f)
if __name__ == '__main__':
#スクリプトを実行するバッチファイルを生成
fname=os.path.splitext(os.path.basename(sys.argv[0]))[0]+'.bat'
with open(fname,'w') as f:f.write(f'python "{sys.argv[0]}" \n pause \n')
#print()で出力させるファイルを設定
f = open('memo.txt','w')
#日付と保存フォルダを指定して、株価データをダウンロード
date_str='2020-08-21' #ここを変更して利用する
year, month, day = date_str.split('-')
fileName = 'T{0}{1}{2}.zip'.format(year[-2:], month, day)
#ダウンロードファイルの存在を確認。なければ、ダウンロードを実行
if not os.path.exists(fileName):
fileName=download_mujinzo(date_str=date,folder='./')
else:
print(f'ファイル:{fileName}はすでにダウンロード済みです')
print('*'*30,file=f)
print(f'Download Filename:{fileName}',file=f)
print('*'*30,file=f)
#zipファイルを読み込み、DataFrameに変換する → その後列名をセットする
df=pd.read_csv(fileName,encoding="shift_jis",header=None)
df.columns=['date','code','no','name','open','high','low','close','volume','market']#列名をセット
df=df.sort_values('code')
#データフレームの内容を表示 year, month, day = date_str.split('-')
print('*'*10,'DataFrame information','*'*10)
print(df.info()) #各列の情報
print('*'*10,'DataFrame first 10 data ','*'*10)
print(df.head(50)) #先頭10個のデータ表示
print('*'*30)
#csvファイルに書き出す 銘柄リスト出力
code,no,name,open,high,low,close,volume,market,date = kabu_df2ndarray(df)
name2=[]
for i in range(len(df)):
try:
name2.append(name[i].split(' ')[1].strip())
#name2.append(haba_cal(name[i].split(' ')[1].strip(),haba=20,embedded='',hoko='<')) except: name2.append(name[i]) df['name2']=name2 savefile='./code_list.csv' df[['code','name2']].to_csv(savefile,encoding='utf_8_sig') #UTF-8 BOM付ファイル書き込み エクセルで文字化け防止 #市場の種類をリスト化 market_list=df['market'].unique() print(market_list,file=f) #['東証1部' '東証2部' 'JAQ' '東証マ' '名古セ' '名証1部' '外国' '名証2部' '名証セ' '東証M'] print(df['market'].value_counts(),file=f) #東証1部 2462 #JAQ 696 #東証2部 488 #東証マ 335 #名証2部 51 #名証セ 12 #名証1部 6 #外国 2 #名古セ 1 #東証M 1 #データを整形して桁をそろえて表示させる【東証2部】 print('データを整形して桁をそろえて表示させる【東証1部】',file=f) df1=df.loc[df['market']=='東証1部' ] kabu_seikei(df1,1,30) kabu_seikei2(df1,1,30,f=f) #データを整形して桁をそろえて表示させる【東証2部】 print('データを整形して桁をそろえて表示させる【東証2部】',file=f) df2=df.loc[df['market']=='東証2部' ] kabu_seikei(df2,1,30) kabu_seikei2(df2,1,30,f=f) #データを整形して桁をそろえて表示させる【東証マ】 print('データを整形して桁をそろえて表示させる【東証マ】',file=f) dfm=df.loc[df['market']=='東証マ' ] kabu_seikei(dfm,1,30) kabu_seikei2(dfm,1,30,f=f) #データを整形して桁をそろえて表示させる【JAQ】 print('データを整形して桁をそろえて表示させる【JAQ】',file=f) dfJ=df.loc[df['market']=='JAQ' ] kabu_seikei(dfJ,1,30) kabu_seikei2(dfJ,1,30,f=f) #複数の市場のデータを抽出する 【東証1部】or【東証2部】 print('複数の市場のデータを抽出する 【東証1部】or【東証2部】',file=f) df1_2=df.loc[(df['market']=='東証1部')| (df['market']=='東証2部')] kabu_seikei(df1_2,1,100) kabu_seikei2(df1_2,1,100,f=f) #全データから売買代金が20億円以上の銘柄を抽出する print('全データから売買代金が20億円以上の銘柄を抽出する',file=f) df['baibai'] = df['close']*df['volume']/100000000 df_baibai=df.loc[df['baibai']>=20]
df_baibai=df_baibai.sort_values('baibai',ascending=False)
#print(df_baibai)
code,no,name,open,high,low,close,volume,market,date = kabu_df2ndarray(df_baibai)
baibai = df_baibai['baibai'].values
start=1
end=50
start=start-1
end=end-1
#データを整形して桁をそろえて表示させる【売買代金条件で抽出】
print('{:5} {:4} {:2} {:^20} {:>10} {:>10} {:>10} {:>10} {:>10} {:<15} {:>10} {:<20}'.format ('No','code','no','name','open','high','low','close','volume','market','date','売買代金[億]'),file=f) print('-'*120,file=f) for i in range(len(df_baibai)): if i>=start and i<=end: print('{:5} {} {} {} {:10} {:10} {:10} {:10} {:10} {:10} {:>10} {:>10.1f}'.format
(i+1,code[i],no[i],haba_cal(name[i].split(' ')[1].strip(),haba=20,embedded='',hoko='<')
,open[i],high[i],low[i],close[i],volume[i],haba_cal(market[i].strip(),haba=15,embedded='',
hoko='<'),date[i],baibai[i]),file=f) else: break print('*'*120,file=f) #始値→高値の割合が高い順 df['oh_ratio'] = (df['high']-df['open'])/df['open']*100 df_oh=df.sort_values('oh_ratio',ascending=False) df_oh=df_oh.loc[df_oh['market']=='東証1部' ] code,no,name,open,high,low,close,volume,market,date = kabu_df2ndarray(df_oh) oh_ratio = df_oh['oh_ratio'].values #データを整形して桁をそろえて表示させる【始値→高値の上昇率ソートで抽出】 print('{:5} {:4} {:2} {:^30} {:>10} {:>10} {:>10} {:>10} {:>10} {:<15} {:>10} {:<20}'.format ('No','code','no','name','open','high','low','close','volume','market','date','high-open ratio'),file=f) print('-'*120,file=f) start=1 end=50 start=start-1 end=end-1 for i in range(len(df_oh)): if i>=start and i<=end: print('{:5} {} {} {} {:10} {:10} {:10} {:10} {:10} {:10} {:>10} {:>4.1f}'.format
(i+1,code[i],no[i],haba_cal(name[i],haba=30,embedded='',hoko='<')
,open[i],high[i],low[i],close[i],volume[i],haba_cal(market[i].strip(),haba=15,embedded='',
hoko='<'),date[i],oh_ratio[i]),file=f) else: break print('*'*120,file=f) #ndarrayでfor文を使った抽出例 code,no,name,open,high,low,close,volume,market,date = kabu_df2ndarray(df) oh_ratio=[] for i in range(len(df)): oh_ratio.append(((high[i]-open[i])/open[i])*100) df['oh_ratio2']=oh_ratio df_oh=df.sort_values('oh_ratio2',ascending=False) df_oh=df_oh.loc[df_oh['market']=='東証1部' ] #表示整形するために再度、ndarray化する code,no,name,open,high,low,close,volume,market,date = kabu_df2ndarray(df_oh) oh_ratio = df_oh['oh_ratio'].values #データを整形して桁をそろえて表示させる【始値→高値の上昇率ソートで抽出】 print('{:5} {:4} {:2} {:^30} {:>10} {:>10} {:>10} {:>10} {:>10} {:<15} {:>10} {:<20}'.format ('No','code','no','name','open','high','low','close','volume','market','date','high-open ratio'),file=f) print('-'*120,file=f) start=1 end=50 start=start-1 end=end-1 for i in range(len(df_oh)): if i>=start and i<=end: print('{:5} {} {} {} {:10} {:10} {:10} {:10} {:10} {:10} {:>10} {:>4.1f}'.format
(i+1,code[i],no[i],haba_cal(name[i],haba=30,embedded='',hoko='<')
,open[i],high[i],low[i],close[i],volume[i],haba_cal(market[i].strip(),haba=15,embedded='',
hoko='<'),date[i],oh_ratio[i]),file=f)
else:
break
print('*'*120,file=f)
f.close() #print()用ファイルをクローズ
#一時停止のための入力待ち
a=input('Program finished!')
pandasはいいね~
今回、locにフォーカスを当てて記事を書きましたが、奥が深いので、さまざまなテクニックも紹介したいと思います。基礎的な以下の記事もぜひぜひ参考にしてくださいね。


コメント