
カスタム関数のカテゴリーでは、便利に使えるオリジナル関数を紹介します。
※カスタム関数は、一般的には「ユーザー定義関数」と呼ばれています
get_east_asian_width_count() 半角全角混在の文字列の正確な文字幅を計算する関数
Python標準のライブラリー「unicodedata」を使って、半角と全角が混在していても文字の幅を正確に計算することができる関数です。
引用したサイトはこちら → nkmkさんのサイト
def get_east_asian_width_count(text):
import unicodedata
#半角と全角の幅を求める(半角:1 全角:2)
count = 0
for c in text:
if unicodedata.east_asian_width(c) in 'FWA':
count += 2
else:
count += 1
return count
この関数に全角半角の混在した文字列textを渡すと、半角を1文字、全角を2文字として、全文字幅の数を返してくれます。(便宜上、関数内にimport文を入れていますが、先頭で宣言してください)
それでは、このget_east_asian_width_count()を使ったプログラム例です。さきほどの関数の下に以下のコードを書いて実行してみると。
if __name__ == '__main__':
# 1234567890123456789012345678901 31文字
# 2468023457913579135791357913579 59文字
text="この文字列は123のような半角と、123のような全角文字が混在"
mojisu=get_east_asian_width_count(text)
len1=len(text)
print("全角も半角もlen関数で計算すると幅は:",len1)
#全角も半角もlen関数で計算すると幅は: 31
print("混在を考慮して計算した文字列の幅は:",mojisu)
#混在を考慮して計算した文字列の幅は: 59
コードの中に入れているコメント文のように、普通にlen()関数を使って計算した文字数は31文字ですが、全角を2、半角を1として計算した場合には59文字となりました。
11行:#全角も半角もlen関数で計算すると幅は: 31
14行:#混在を考慮して計算した文字列の幅は: 59
haba_cal(s,haba=20,embedded=”,hoko='<‘) 全角半角混在でも指定した文字幅で出力する
それでは、本日の本題です。さきの例にあったget_east_asian_width_count()を使えば、全角半角混在していても実際の文字幅を正確に計算してくれるので、文字幅をそろえたいときに応用できそうです。
次のカスタム関数は、混在文字列をs、指定文字幅をhaba,埋め込み文字をenbedded,文字寄せ指定をhokoとして、引数に渡すと整形された文字列を返してくれます。
’文字列’.format()メソッドについては、こちらで説明しています。→format() はprint()と組み合わせてよく使う
def haba_cal(s,haba=20,embedded='',hoko='<'):
#半角と全角混在でも幅を揃える文字を返す
#s:文字列 haba:揃えたい文字数
#embeged:埋め込みい文字
#hoko:左寄せ< 中央揃え^ 右寄せ>
n=get_east_asian_width_count(s)
new_haba=haba+len(s)-n
ss='{:'+embedded+hoko+str(new_haba)+'}'
final_s=ss.format(s)
return final_s
#F - East Asian Full-width
#H - East Asian Half-width
#W - East Asian Wide
#Na - East Asian Narrow (Na)
#A - East Asian Ambiguous (A)
#N - Not East Asian
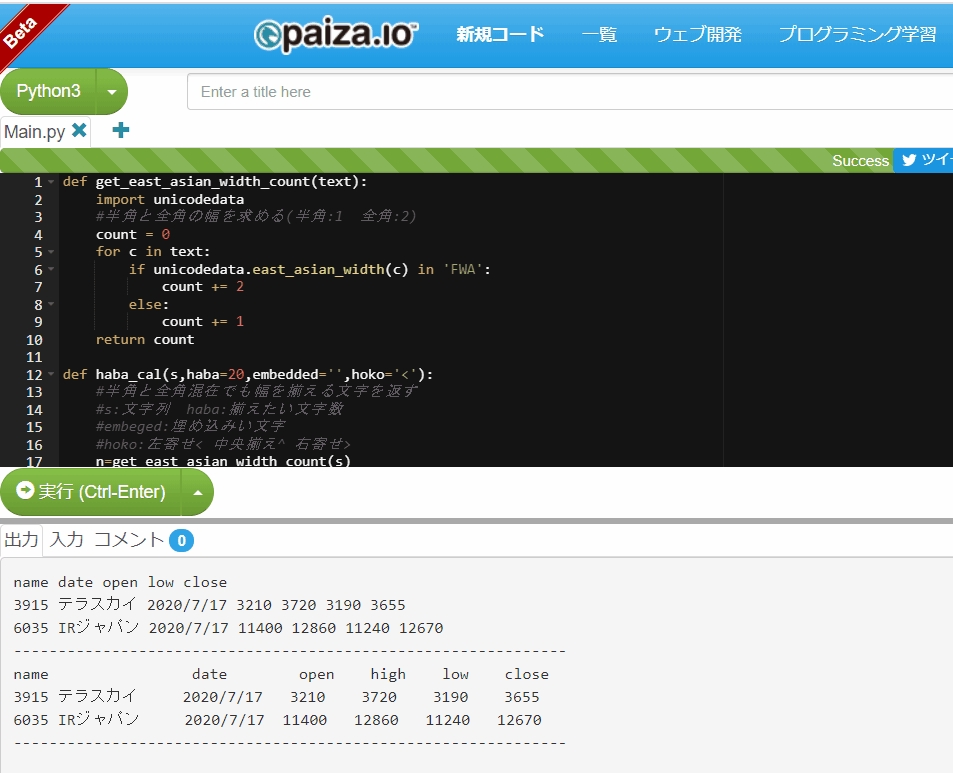
2020/7/17のテラスカイとIRジャパンの株価データを表示してみます。openは始値、highは高値、lowが安値、closeが終値を示しています。(今後、株価データを例によく使っていきます)
24行目以降のコメント文が実際の出力ですが、最初の項目名、テラスカイのデータ、IRジャパンのデータすべて桁がうまく揃っていませんので、haba_calを使って整形したいと思います。
以下が、整形のための設計です
name:証券コードと銘柄名を合わせて20文字
date:10文字
open、high,low ,close:8文字
としてみます。
if __name__ == '__main__':
name1="3915 テラスカイ"
date1="2020/7/17"
open1="3210"
high1="3720"
low1="3190"
close1="3655"
name2="6035 IRジャパン"
date2="2020/7/17"
open2="11400"
high2="12860"
low2="11240"
close2="12670"
print("name","date","open","low","close",sep=" ")
print(name1,date1,open1,high1,low1,close1,sep=" ")
print(name2,date2,open2,high2,low2,close2,sep=" ")
name0_s=haba_cal('name',haba=20,embedded=' ',hoko='<')
date0_s=haba_cal('date',haba=10,embedded=' ',hoko='<')
open0_s=haba_cal('open',haba=8,embedded=' ',hoko='^')
high0_s=haba_cal('high',haba=8,embedded=' ',hoko='^')
low0_s=haba_cal('low',haba=8,embedded=' ',hoko='^')
close0_s=haba_cal('close',haba=8,embedded=' ',hoko='^')
print('-'*62)
print(name0_s+date0_s+open0_s+high0_s+low0_s+close0_s)
name1_s=haba_cal(name1,haba=20,embedded=' ',hoko='<')
date1_s=haba_cal(date1,haba=10,embedded=' ',hoko='<')
open1_s=haba_cal(open1,haba=8,embedded=' ',hoko='^')
high1_s=haba_cal(high1,haba=8,embedded=' ',hoko='^')
low1_s=haba_cal(low1,haba=8,embedded=' ',hoko='^')
close1_s=haba_cal(close1,haba=8,embedded=' ',hoko='^')
print(name1_s+date1_s+open1_s+high1_s+low1_s+close1_s)
name2_s=haba_cal(name2,haba=20,embedded=' ',hoko='<')
date2_s=haba_cal(date2,haba=10,embedded=' ',hoko='<')
open2_s=haba_cal(open2,haba=8,embedded=' ',hoko='^')
high2_s=haba_cal(high2,haba=8,embedded=' ',hoko='^')
low2_s=haba_cal(low2,haba=8,embedded=' ',hoko='^')
close2_s=haba_cal(close2,haba=8,embedded=' ',hoko='^')
print(name2_s+date2_s+open2_s+high2_s+low2_s+close2_s)
print('-'*62)
#name date open low close
#3915 テラスカイ 2020/7/17 3210 3720 3190 3655
#6035 IRジャパン 2020/7/17 11400 12860 11240 12670
#--------------------------------------------------------------
#name date open high low close
#3915 テラスカイ 2020/7/17 3210 3720 3190 3655
#6035 IRジャパン 2020/7/17 11400 12860 11240 12670
#--------------------------------------------------------------
60行以降が、出力結果を表していますが、haba_cal()を使って整形したほうは、きれいに揃っています。print()のsep=’ ‘オプションについてはこちらで詳しく解説しています。→print() を極める たかがprint、されどprint
このように全角、半角が混在している文字列を幅をそろえて整形したいときに使えそうですね。
ちなみにpaiza.ioでも上記のコードはうまく動きました。paiza.ioについてはこちらで→Python初心者の方へ、脱初心者は5分で終わる![環境構築なし]
今日のところはこのへんで



コメント