Pythonの内包表記は見にくいけど簡潔
Pythonのプログラムの中で、たまに「リスト内包表記」を目にすると思います。正直、見にくいし、構造がわかりにくいし、なんのためにあるのかよくわからない人も多くおられると思います。
確かにそのとおりです!
でも、他人のプログラムをコピペしたり、読んで理解するときに「何をしているのかわからない」では、困ることもあると思いますので、せめて、内容が理解できるように知識として持っておきたいと思い記事をまとめました。
あと、もし慣れれば、簡潔に表現できるので、コードの行数が減らせたり、逆に一発で理解できる場合もあるので、まったく役に立たないというわけではないと思います。
内包表記にはリスト内包表記、集合内包表記、辞書内包表記と3つほどあります。順番に紹介します。
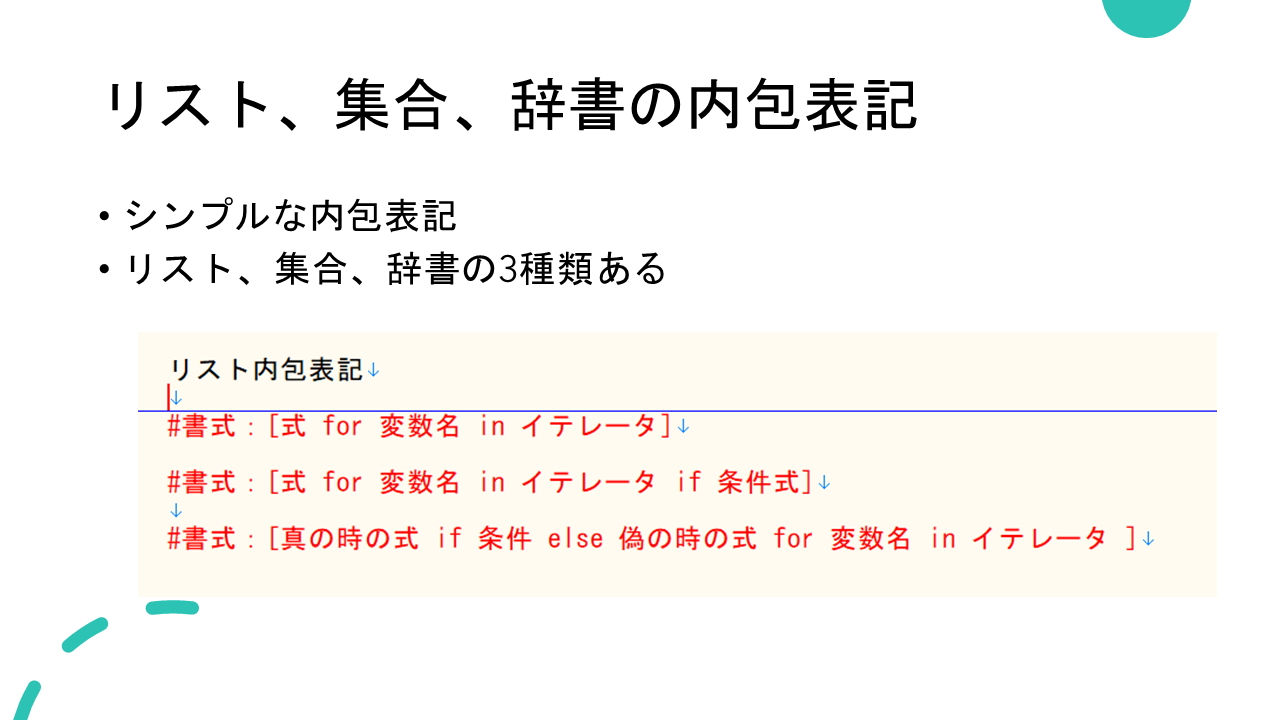
リスト内包表記の書き方
一番登場回数というか、見かける頻度が高いのがリスト内包表記だと思います。
単純なリスト内包表記の例 [式 for 変数名 in イテレータ]
まず、普通のfor文を使った構文で、リストを作るコードを示します。
list1=[]
for i in range(10):
list1.append(i)
これは、list1というリスト型の変数を空にして、0~9までの整数を格納する単純なコードです。
中身は、[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]となります。
リスト内包表記を使うと
list1=[x for x in range(10)]
こんな感じで、1行でリストを作りだすことができます。
if条件分岐のある例 [式 for 変数名 in イテレータ if 条件式]
次は、if文を使った条件分岐の例です。これも通常のfor文を使った例から示しますと、
list1=[]
for i in range(10):
if i % 2==0 :
list1.append(i)
さきほどと同じく0~9までの整数のループを回していますが、途中で偶数だけをリストに追加しています。
中身は、[0, 2, 4, 6, 8] となります。
リスト内包表記を使うと、1行で記述できます。ここで注意するところは、if部分は最後に記述するというところです。
list1=[x for x in range(10) if x % 2==0]
if~else条件分岐のある例 [真の式 for if 条件式 else 偽の式 変数名 in イテレータ ]
次も条件分岐ですが、条件の式が真の場合と偽の場合に分岐する場合です。これもfor文を使った通常の書き方で示します。
list1=[]
for i in range(10):
if i % 2==0 :
list1.append(f'{str(i)}:偶数')
else:
list1.append(f'{str(i)}:奇数')
0~9の整数をループで回していますが、偶数のときと奇数のときの場合分けを入れています。
list1の中身は、
[‘0:偶数’, ‘1:奇数’, ‘2:偶数’, ‘3:奇数’, ‘4:偶数’, ‘5:奇数’, ‘6:偶数’, ‘7:奇数’, ‘8:偶数’, ‘9:奇数’]
こんな感じにあります。
これをリスト内包表記で書くと、以下の通り。いつも私は、この構造を忘れてしまうのですが、注意してみていただくとif~elseの部分が、さきほどのifだけの場合と異なります。式→if~else→for
という順番であることに気を付けてください。
list1=[f'{str(x)}:偶数' if x % 2==0 else f'{str(x)}:奇数' for x in range(10) ]
複数の変数のネストがある例
リスト内包表記では、for文がひとつだけではなく、2つ以上の複数のネスト構造をとることができます。まずは、通常の書き方でネスト構造を記述してみましょう。
list1=[]
for x in range(3):
for y in range(3):
list1.append([x,y])
xとyという二つの変数を0~2の整数をfor文でループさせています。xが3つ、yが3つで合計9つのリストが生成されることになります。(総当たり戦みたいなものですね)
今回できあがるリスト変数list1の中身は
[[0, 0], [0, 1], [0, 2], [1, 0], [1, 1], [1, 2], [2, 0], [2, 1], [2, 2]]
となります。
これをリスト内包表記で書いてみますと
list1=[[x,y] for x in range(3) for y in range(3)]
となり、たった1行で表現できます。もちろん、list1の中身は同じく
[[0, 0], [0, 1], [0, 2], [1, 0], [1, 1], [1, 2], [2, 0], [2, 1], [2, 2]]
となります。
リスト内包表記の簡単な応用例
リスト内包表記は、とても簡潔に表現できますが、あまり複雑なことはできません。たとえば、pandasのデータフレームのテストデータを簡単に作ることに使ってみるのもいい応用例です。
下記の例は、3列のデータとインデックスの構成を作っています。x_listは0~9までの整数、x2_listはx_listの二乗、x_list3はx_listの3乗を計算しています。date_listは、日付を10日間連続で生成しています。最後のy_listはインデックスのために作ったa~jまでの一文字のアルファベット記号です。
import pandas as pd
from datetime import datetime, timedelta
print('*** pandasのDataFrameのテストサンプルを作るとき***')
#各要素の配列をリスト内包表記で生成
x_list=[x for x in range(10)]
x2_list=[x**2 for x in range(10)]
x3_list=[x**3 for x in range(10)]
date_list = [datetime(2020, 11, 10) + timedelta(days=i) for i in range(10)]
y_list=[s for s in 'abcdefghij']
#データフレームに一つ目の要素とインデックスをセット
df=pd.DataFrame(x_list,index=y_list,columns=['x'])
#二つ目以降の要素をそれぞれ追加
df['X2']=x2_list
df['X3']=x3_list
df['Date']=date_list
pandasをpdで使えるようにしておき、pd.FataFrame(リスト、index=インデックス用リスト、columuns=リストの列名リスト)という書式でまずは、ひとつめの要素列とインデックスをセットします。
そのあとはdf[列名]=リストデータ という形式で次々に追加していけば、簡単にデータフレームのテストデータが作れます。
空のデータフレームを作ってから、要素を追加したり、インデックスを追加したり、列名をセットする方法でもOKです。
#空のデータフレームを作る
df=pd.DataFrame()
#二つ目以降の要素をそれぞれ追加
df['X']=x_list
df.index=y_list #注意ポイント:先にデータ要素を入れてからでないとエラーになる
df['X2']=x2_list
df['X3']=x3_list
df['Date']=date_list
注意事項としては、一つ目の要素列を追加したあとにインデックスをセットしないとエラーがでてしまいます。これは、最初に空のデータフレームを作成した場合にデータ数がゼロのために起こります。順番を間違いないようにしましょう。
ちなみに、今回テスト的に作ったデータフレームの内容は、以下のようになります。
x X2 X3 Date a 0 0 0 2020-11-10 b 1 1 1 2020-11-11 c 2 4 8 2020-11-12 d 3 9 27 2020-11-13 e 4 16 64 2020-11-14 f 5 25 125 2020-11-15 g 6 36 216 2020-11-16 h 7 49 343 2020-11-17 i 8 64 512 2020-11-18 j 9 81 729 2020-11-19
ちょっと脱線しますが、インデックスを番号として付けなおすのはreset_index()を使います。
df2=df.reset_index()
中身は以下のように、元のインデックスはindexという列名で残ります。
index X X2 X3 Date 0 a 0 0 0 2020-11-10 1 b 1 1 1 2020-11-11 2 c 2 4 8 2020-11-12 3 d 3 9 27 2020-11-13 4 e 4 16 64 2020-11-14 5 f 5 25 125 2020-11-15 6 g 6 36 216 2020-11-16 7 h 7 49 343 2020-11-17 8 i 8 64 512 2020-11-18 9 j 9 81 729 2020-11-19
元のインデックスは消去したい場合は、dropオプションをTrueにします。
df3=df.reset_index(drop=True)
以下のように、元のインデックスの列は消えました。
X X2 X3 Date 0 0 0 0 2020-11-10 1 1 1 1 2020-11-11 2 2 4 8 2020-11-12 3 3 9 27 2020-11-13 4 4 16 64 2020-11-14 5 5 25 125 2020-11-15 6 6 36 216 2020-11-16 7 7 49 343 2020-11-17 8 8 64 512 2020-11-18 9 9 81 729 2020-11-19
集合内包表記の書き方
リスト内包表記をよく目にしますが、集合も内包表記できます。次の例では、アルファベットを一文字ずつ取り出して、集合set1に入れています。
set1={s for s in 'abcdefghij'}集合set1の内容は {‘d’, ‘f’, ‘h’, ‘b’, ‘c’, ‘i’, ‘a’, ‘g’, ‘j’, ‘e’} となります。
集合(set)についての復習
集合は、リストのように配列データですが、ひとつ大きな特徴があります。それは「重なった同じデータはない配列」ということです。
では、内包表記を使って、わざと、同じ文字を集合にセットしてみましょう。
set2={s for s in 'aaaaabbbbbcccc'}
このようにa,b,cは複数回登場しています。この場合にset2の中身は
{‘a’, ‘c’, ‘b’}
という具合に集約されることがわかります。
その他、復習事項として、いくつか集合の演算方法も紹介しておきます。
#集合の追加 .add()
set2.add('z')
print(set2)
#重複しない要素を返す .union()
print(set1.union(set2))
print(set1 | set2) #.union()と同じ結果
#どちらにも含まれる要素を返す .intersection()
print(set1.intersection(set2))
print(set1 & set2) #.intersection()と同じ結果
#set1からset2の要素を省く .difference()
print(set1.difference(set2))
print(set1 - set2) #.difference()と同じ結果
#set1とset2 どちらかにしか存在しない要素を返す .symmetric_differencw()
print(set1.symmetric_difference(set2))
print(set1 ^ set2) #.symmetric_differencw()と同じ結果
#集合から要素を除去する(要素がない場合はエラーが出る)
set2.remove('a')
print(set2)
集合内包表記で条件をつける場合の例
次の例は、a~zのアルファベットの一文字ずつを集合にセットして、zだけを削除する例です。まずは、通常の書き方を示します。
set2={s for s in 'abcdefghijklmnopqrstuvwxyz'}
list1=list(set2)
for x in list1:
print(x)
if x == 'z':
set2.remove(x)
print('要素を削除しました')
ここで注意ポイントは、集合を一度、リストに入れている点です。もし、直接set2を使うと、削除した時点で、もとの配列データ数が変化してしまうため、エラーになってしまうためです。
それでは、集合内包表記で表現してみましょう
{set2.remove(x) for x in list(set2) if x=='a'}
さきほどと同じように注意ポイントはset2を一度list(set2)のようにリストにしておく必要があることです。
このプログラムを実行した結果、set2から「a」がなくなります。(さっきのコードでzもなくなっています)
{'c', 'x', 'y', 'n', 'b', 'e', 'p', 'v', 'o', 'k', 'u', 'g', 'w', 'd', 'q', 'f',
'm', 's', 'l', 'i', 'j', 'h', 'r', 't'}
たくさん文字があるので、わかりにくいのですが、a,zはありません。集合は、順番が最初に作ったときから変化していることにお気づきになったと思います。順番は決まらないことも覚えておきましょう。
辞書内包表記
リスト内包表記、集合内包表記とご説明しました。内包表記のトリは、辞書内包表記です。
辞書はキーと値の組み合わせでできていて{‘key1′:vallue1,’key2’:vallue2,・・・}のような構造をしています。
これを内包表記で生成してみましょう
#辞書を内包表記をリストから使って生成
key1=['apple','orange','banana']
value1=['リンゴ','みかん','バナナ']
dict1={k:v for k,v in zip(key1 ,value1)}
キーのリストと値のリストをそれぞれkey1、value1として設定したあとに出てくるのが内包表記ですが、zip関数を使って、二つのリストから同時に値を取り出しています。この場合、kがキー用の変数で、vが値用の変数になっています。
そして、k:vという形にすれば、辞書の要素が順番にできあがるという仕組みです。
一番外側の波かっこも {k:v} も辞書の場合に使うものです。
でも要素数が少ない場合あ、普通に書いた方が一行で済んだりします(笑)
dict2=dict([('dog','犬'),('cat','猫'),('monkey','猿')])
要素数が多かったり、演算が必要な場合は、もちろん内包表記の方がシンプルです。
dict3={str(x):str(x**3) for x in range(5) }
この例では、キーの数値の3乗を値に入れている辞書例です。
これを実行すると
{'0': '0', '1': '1', '2': '8', '3': '27', '4': '64'}と辞書が出来上がります。
辞書について復習
簡単に辞書について復習しておきましょう。
辞書の結合(python Ver3.5から使える方法です)
#参考:辞書の結合(注意ポイント:python 3.5以降しか使えない。結合の場合は、キーと値は型が同じでないとだめ)
dict4=dict(**dict1,**dict2,**dict3)
辞書のキーと値の取り出し方
print('*'*30,'特定のキーの値を取得')
print(dict4['apple']) #特定のキーの値を取得
print('*'*30,'キーだけをすべて取り出す')
print(dict4.keys()) #キーだけ取り出す
print('*'*30,'リストに変換して指定したキーを取り出す')
a=list(dict4.keys()) #リストに変換して指定して取り出す
print(a[0])
print('*'*30,'内包表記を使って、最初の10個だけキーを取り出す')
print([k for i,k in enumerate(dict4.keys()) if i <= 10]) #最初の10個だけキーだけ取り出す(リストが返る)
print('*'*30,'辞書の値だけ取り出す')
print(dict4.values()) #値だけ取り出す
print('*'*30,'リストに変換して指定した値を取り出す')
b=list(dict4.values()) #リストに変換して指定して取り出す
print(b[0])
print('*'*30,'内包表記を使って、最初の10個だけ値を取り出す')
print([k for i,k in enumerate(dict4.values()) if i <= 10]) #最初の10個だけ値を取り出す(リストが返る)
print('*'*30,'辞書のキーと値のペアを取り出す')
print(dict4.items()) #キーと値のペアを取り出す
print('*'*30,'辞書のキーと値のペアをリスト化して指定したペアを取り出す')
c=list(dict4.items())
print(c[0]) #リストから指定した順番のキーと値のペアを取り出す
print('*'*30,'辞書のキーが存在するか評価する')
if 'apple1' in dict4.keys():
print('キーは存在しました')
else:
print('キーは存在しませんでした')
内包表記のまとめ
以上が、リスト内包表記、集合内包表記、辞書内包表記でした。
日ごろは、あまり使わないかもしれませんが、見慣れるとシンプルでコードが簡潔に感じるかもしれません。
速度については、測定していませんが、また、機会があれば、通常のfor文を使った場合と、内包表記の場合の速度対決をしてみたいと思います。


コメント