カスタム関数シリーズでは、便利に使えるオリジナル関数を紹介しています。
※カスタム関数は、一般的には「ユーザー定義関数」と呼ばれています
文字列検索 文字列.find(検索文字列)
文字列を検索するにはfind()メソッドを使います。
見つかれば、そのインデックス(文字列中の位置)を返し、見つからなかったら-1を返します。
s = '12345678901234567890'
search_s = '2345'
n=s.find(search_s)
print(n) #検索位置は1この例では、2345が元の文字列の2番目から始まっているので、インデックス1が表示されます。
しかし、この文字列sには、2345は二か所あります。
検索開始位置が指定できる 文字列.find(検索文字列,開始位置)
find()は、検索開始位置を指定できます。
n=s.find(search_s,2)
さきほどの結果1にひとつ足した2から始めればよいということになります。
でも、最初にヒットとした位置がわからなければ、開始位置が決定できません。
検索文字列が2個以上ヒットするケースを一般化したいですね。
検索文字列が二か所以上ヒットする場合に対応 searchall()
ここでカスタム関数(ユーザー定義関数)searchall()を作ることにします。そのために文字列.count(検索文字列)という検索文字列が何個あるのか調べるメソッドを利用することにします。
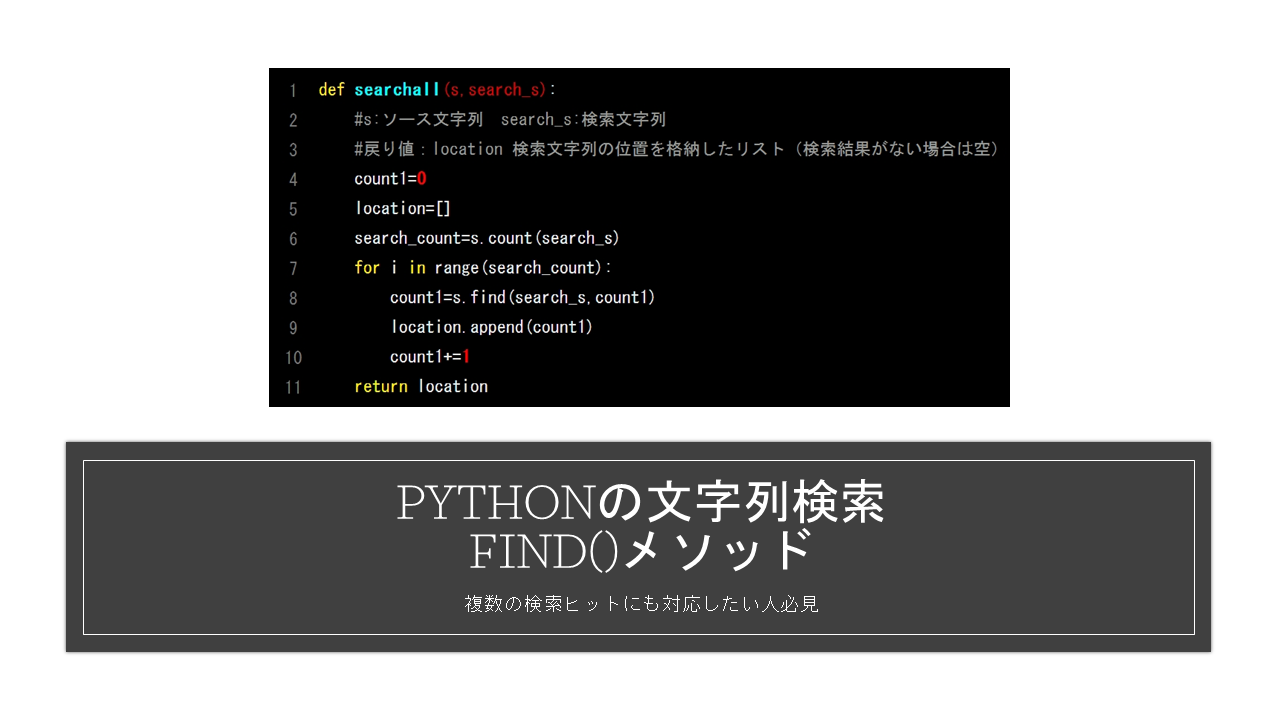
def searchall(s,search_s):
#s:ソース文字列 search_s:検索文字列
#戻り値:location 検索文字列の位置を格納したリスト(検索結果がない場合は空)
count1=0
location=[]
search_count=s.count(search_s)
for i in range(search_count):
count1=s.find(search_s,count1)
location.append(count1)
count1+=1
return location
search_count=s.count(search_s)
ここで、search_countには、検索ヒットした数が入ります。
s = ‘12345678901234567890’
search_s = ‘2345’
とすると、検索ヒットするのは二か所あるため、search_countは2ということになります。
count1=s.find(search_s,count1)
さきほど出てきたfind()メソッドにより、検索ヒットした位置をcount1に格納します。
location.append(count1)
この位置情報(数値)をlocationというリスト変数に追記します。
count1+=1ヒットした次の文字から検索を行うためにカウンターcount1を1増加させて、繰り返します。
return location最後に検索ヒット位置を格納したリスト変数locationを返すようにします。
searchall(s,search_s)の使い方
s = '12345678901234567890'
search_s = '2345'
list1 = searchall(s,search_s)
print(list1) #[1,11]
さきほどと同じように元の文字列sと検索文字列search_sを設定します。
そして、この関数の戻り値をlist1というリスト変数に入力して、print関数で表示させます。
この場合、[1,11]と表示されます。(順番で言い換えると、2番目と12番目に見つかりました)
サンプルコード:文字列、検索文字列、ヒット位置を明示してみよう
おまけのサンプルですが、文字列に対して検索文字列を設定した場合にどの位置にヒットしたかを明確に表示するような関数を作ってみました。
def search_disp(s,search_s):
location=searchall(s,search_s)
print(f'Source : {s}')
print(f'Search Word: {search_s}')
if len(location)>0:
n=0
for i,num in enumerate(location):
ss=s[n:num]
se=s[num+len(search_s):]
print(f'{i+1:2} :{num:2d} : {ss}**{search_s}**{se}')
else:
print('===== not find! =====')ここでは、searchall()関数で得られた、ヒット位置情報のリストを使って、ヒット位置を**で挟んで表示するようにしてみました。このコードを実行するとこうなります。
[1, 11] Source : 12345678901234567890 Search Word: 2345 1 : 1 : 1**2345**678901234567890 2 :11 : 12345678901**2345**67890
ちゃんと、ヒットした位置が**2345**のように強調されていることがわかります。
ss=s[n:num]
se=s[num+len(search_s):]ssは検索文字列前の文字列、seは検索文字列後の文字列を示しています。検索文字列を二度表示しないようにseで、検索文字列の文字数分だけずらしている工夫をしています。
別解:searchall2()
def searchall2(s,search_s):
#s:ソース文字列 search_s:検索文字列
#戻り値:location 検索文字列の位置を格納したリスト(検索結果がない場合は空)
cnt=0
location=[]
n=0
while True:
n=s.find(search_s,cnt)
if n != -1 :
location.append(n)
cnt=n+1
else:
break
return location
さきほどは、count()メソッドであらかじめ、検索ヒット数を調べてから行ったのですが、このcount()メソッドを使わずに作成したカスタム関数searchall2()です。検索文字列が見つからなかった場合にfind()メソッドが-1を返すことを利用して、ループを抜け出しています。
このコードは、前作より3行コードが長くなっていますので、前作のほうがシンプルに書けていることになります。


コメント